Polling
September 28, 2020
As we saw last week, economic indicators alone may not be highly predictive of presidential election outcomes, especially during this time. One way to improve our model is to use polling data, since these ideally reflect which candidate poll respondents may actually vote for. Similar to economic indicators, the predictive power of polls goes up as we get closer to elections. Using aggregated polling data, we can test out how polling data alone and polling plus economic indicators data affect our model.
Building a Model using Polling Data
Given state level polling data, we aggregate all of the polling data by state and year and build separate models for each state. Then, we use 2020 polling data to predict the incumbent party’s vote share for the 2020 election. The polling data included in our model only include polls completed within 60 days of the election, given that polls are more predictive closer to elections. Data for Illinois, Rhode Island, South Dakota, and Wyoming are not included in the polling dataset and thus we are not able to make predictions for those states.
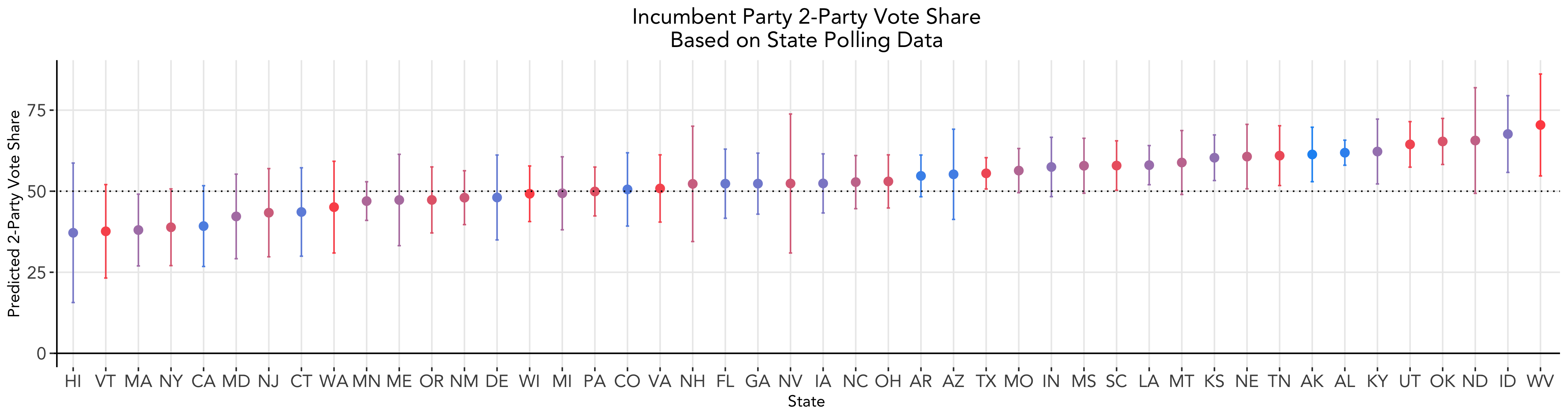
Compared to last week’s state level predictions, this polling model shows improved accuracy, given that no prediction intervals include values below 0 or above 100 as some did in our economic indicators model. Overall, Trump is predicted to win 29 states per this model, and taking the average across the states included yields a national popular vote share of 52.9.
Weighted Ensemble: Incorporating Economic Data
We can also create a weighted ensemble where we incorporate both polling data and economic indicators from last week. Following FiveThirtyEight’s method, we give polling data more weight relative to economy data as the election draws closer. The weight the polling data receives in our model grows exponentially as time goes on. At the time of running this model, there were 37 days left until the election. Given what we learned last week, we select GDP growth in the 2nd quarter of election years as our economic indicator. It is important to note that the GDP growth used is at the national level, not the state level, and thus does not account for the important local variations we see in the indicator.
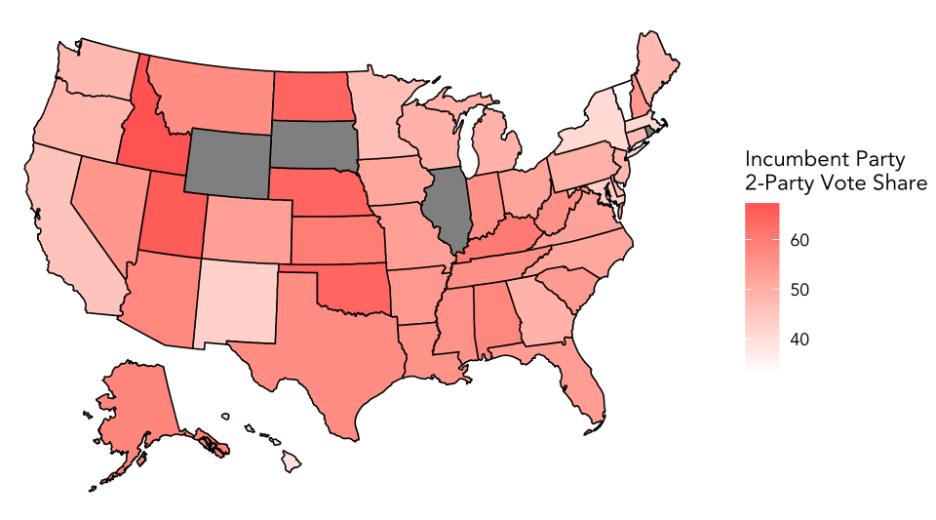
The following map shows the incumbent party predicted 2-party vote share for each state, with deeper tints of red indicating a higher predicted vote share. Illinois, Rhode Island, South Dakota, and Wyoming are shaded gray on the map because, again, their data was not included in the polling dataset.
Here are the prediction numbers:


Some interesting findings to point out:
- This model predicts Trump to win the popular vote in 28 states. The one state that differs from the poll-only model is Georgia. In addition, Trump’s national popular vote share is predicted to be 52.5, similar to our above model’s prediction.
- In states considered solidly democratic per the New York Times such as California, Hawaii, New York, and Vermont, this model predicts incumbent party vote share as at least a few percentage points below 50%.
- In states considered solidly republican such as Idaho, Nebraska, North Dakota, and Oklahoma, this model predicts incumbent party vote share many percentage points above 50%.
- Swing states Florida, Iowa, North Carolina are predicted to go to Trump, while Georgia, Pennsylvania, Michigan, and Wisconsin are predicted to go to Biden.
Caveats to Polling Data
It is important to acknowledge a few caveats to using polling data in our prediction model. Polls vary greatly in quality - depending on factors including how the poll was conducted, how the polling sample was drawn, and wording of poll questions, the relative support for political candidates that we gather from polls may not be accurate. Even if the polling data we use is representative of the population, the voting population this year may be different due to factors related to the pandemic.
Nevertheless, as Gelman and King suggest, “much evidence exists to conclude that survey responses are related to actual voting.” Aggregated polling data can help us uncover useful information about voters, especially as the election draws closer.
Thanks to Cass for helping me brainstorm ideas for this blog post.